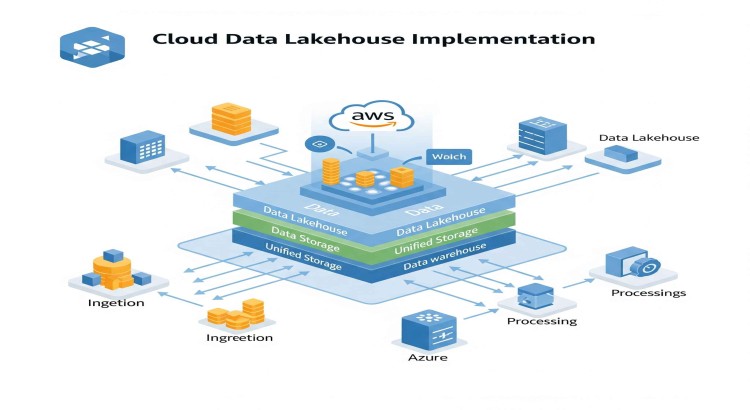
Cloud Data Lakehouse Implementation

About this Service
Overview:
The data lakehouse architecture represents the next evolution in data management, seamlessly blending the low-cost storage and flexibility of a data lake with the ACID transactions, schema enforcement, and data governance capabilities of a data warehouse. This hybrid approach addresses the limitations of traditional data lakes (lack of data quality, complex governance) and data warehouses (inflexibility, high cost for raw data). Implementing a data lakehouse allows organizations to support diverse workloads, from traditional BI and reporting to advanced machine learning and real-time analytics, all from a single, unified platform. This service specializes in designing and implementing a robust Cloud Data Lakehouse tailored to your specific data needs, enabling enhanced data quality, simplified data governance, and accelerated time-to-insight.
Target Area/Industry:
This service is ideal for medium to large enterprises, data-driven organizations, and those struggling with data silos, data quality issues in their data lakes, or performance limitations in their traditional data warehouses. Industries with diverse data needs, such as finance, healthcare, e-commerce, and manufacturing, will find this particularly beneficial.
Topic Level/Position:
Cloud Data Lakehouse Implementation is a strategic and advanced discipline within cloud data architecture. It requires deep expertise in both data lake and data warehouse technologies, data modeling, and data governance. It's a critical step for organizations aiming to build a future-proof, unified data platform.
Detailed Scope of Offer:
- Data Strategy & Use Case Analysis: Collaborating with stakeholders to understand current data challenges, future analytics requirements, and key business use cases for the data lakehouse.
- Data Lakehouse Architecture Design: Designing a scalable, cost-effective, and performant data lakehouse architecture on your chosen cloud platform (AWS, Azure, or GCP). This includes selecting appropriate storage (e.g., AWS S3, Azure Data Lake Storage, Google Cloud Storage), compute engines (e.g., Databricks, AWS EMR, Azure HDInsight, Google Dataproc), and table formats (e.g., Delta Lake, Apache Iceberg, Apache Hudi).
- Schema & Data Modeling: Defining flexible schemas for semi-structured and unstructured data in the data lake, alongside structured schemas for the data warehouse layer within the lakehouse. Implementing data modeling best practices for analytical workloads.
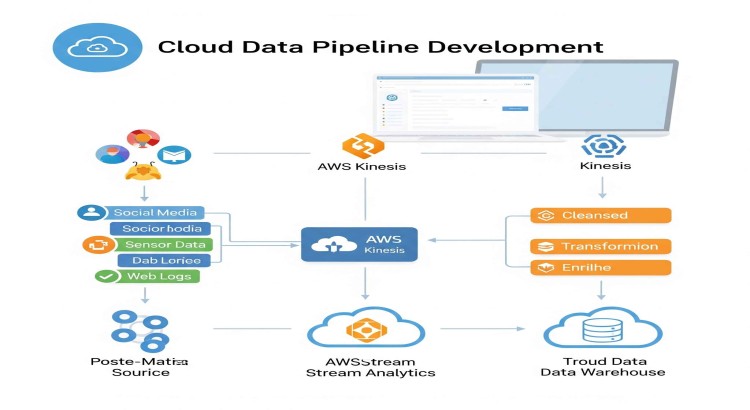
- Data Ingestion & ETL/ELT Pipelines: Building robust data pipelines to ingest raw data into the data lake and then transform it into curated, high-quality datasets within the lakehouse layers. This includes batch and streaming data ingestion.
- Data Governance & Quality Implementation: Implementing data governance policies, including data quality rules, schema evolution management, and access controls (e.g., row-level security, column-level security) directly within the data lakehouse.
- Query Engine & BI Tool Integration: Configuring and optimizing query engines (e.g., Databricks SQL, Amazon Athena, Azure Synapse Analytics, Google BigQuery) for efficient querying of the data lakehouse. Seamless integration with your preferred BI tools (e.g., Tableau, Power BI, Looker).
- Performance Optimization: Fine-tuning data lakehouse configurations, partitioning strategies, and query optimization techniques to ensure high performance for diverse analytical workloads.
- Security & Compliance: Ensuring the data lakehouse adheres to cloud security best practices and compliance requirements (e.g., encryption, network isolation, auditing).
- Documentation & Knowledge Transfer: Providing comprehensive documentation of the data lakehouse architecture, data models, pipelines, and operational procedures. Training your data team on managing and leveraging the new platform.
Tools Utilized:
- Data Lakehouse Platforms: Databricks Lakehouse Platform, AWS Lake Formation, Azure Synapse Analytics, Google Cloud Dataproc/BigQuery.
- Cloud Storage: AWS S3, Azure Data Lake Storage Gen2, Google Cloud Storage.
- Table Formats: Delta Lake, Apache Iceberg, Apache Hudi.
- Data Ingestion/ETL: AWS Glue, Azure Data Factory, Google Cloud Dataflow, Fivetran, Matillion.
- Query Engines: Databricks SQL, Amazon Athena, Presto/Trino, Google BigQuery.
- BI Tools: Tableau, Microsoft Power BI, Looker, Amazon QuickSight.
- Infrastructure as Code (IaC): Terraform, CloudFormation, Azure Resource Manager (ARM).
- Programming Languages: Python, SQL, Scala.
Skills Involved:
- Cloud Data Architecture: Deep expertise in designing and implementing data lakehouse architectures.
- Big Data Technologies: Strong understanding of distributed data processing, data lakes, and data warehouses.
- Data Modeling: Advanced skills in designing schemas for analytical workloads.
- ETL/ELT: Proficiency in building complex data ingestion and transformation pipelines.
- Data Governance: Expertise in implementing data quality, metadata, and access control within data platforms.
- Cloud Platforms: Comprehensive knowledge of AWS, Azure, and/or Google Cloud data services.
- Performance Tuning: Ability to optimize large-scale data systems for query performance and cost.
- Security & Compliance: Understanding of data security and privacy regulations in cloud environments.
- Communication & Consulting: Excellent skills in translating business needs into technical data solutions.
Future Predictions/Considerations:
The data lakehouse will continue to evolve as the dominant data architecture, with increasing emphasis on real-time capabilities, unified governance across all data types, and deeper integration with AI/ML workflows. Data mesh principles will influence how data lakehouses are structured and managed across distributed teams. Serverless compute for data processing will also become more prevalent.
Why Choose Me?
As a Cloud Data Analytics Engineer with 7 years of experience, I excel in designing and implementing scalable data pipelines and analytics solutions on cloud platforms. My background includes developing and optimizing cloud-based data warehouses and ETL processes, improving data processing efficiency by 30% and enabling real-time analytics. I am proficient in leading platforms like BigQuery, Redshift, and Snowflake, ensuring your raw data transforms into actionable insights. My expertise extends to building modern data lakehouse architectures for unified and agile data platforms.
Service Features
- ● Data Strategy & Use Case Analysis
- ● Cloud Data Lakehouse Architecture Design
- ● Data Ingestion & ETL/ELT Pipeline Setup (for 1-2 sources)
- ● Basic Data Modeling & Schema Design
- ● Integration with One BI Tool
- ● Initial Performance & Security Review
- ● Documentation & Knowledge Transfer
About the Seller
Basic
Related Services


Cloud Management
Expert Migration of Atlassian (Jira/Confluence) from Server to Cloud or Data Center


Join as a freelancer or client
Join as a Freelancer
Join as a Client