Cloud Data Pipeline Development

About this Service
Overview:
In the era of big data, the ability to collect, process, and transform vast amounts of raw data into actionable insights is a significant competitive advantage. Cloud data pipelines are the automated workflows that ingest data from various sources, clean and transform it, and then load it into data warehouses or data lakes for analysis. Without efficient pipelines, organizations struggle with data silos, inconsistent data quality, delayed insights, and manual, error-prone processes. This service specializes in designing and building robust, scalable, and automated cloud data pipelines that ensure timely, reliable, and high-quality data delivery for your analytics and business intelligence initiatives.
Target Area/Industry:
This service is crucial for any organization looking to leverage data for decision-making, particularly those with diverse data sources, large data volumes, or a need for real-time analytics. This includes e-commerce, finance, marketing, healthcare, and technology companies. It's ideal for businesses seeking to build a modern data platform in the cloud.
Topic Level/Position:
Cloud Data Pipeline Development is a core discipline within cloud data engineering. It requires strong expertise in cloud data services, ETL/ELT methodologies, data modeling, and programming. It's a foundational component for any modern data analytics strategy, enabling efficient data flow and preparation.
Detailed Scope:
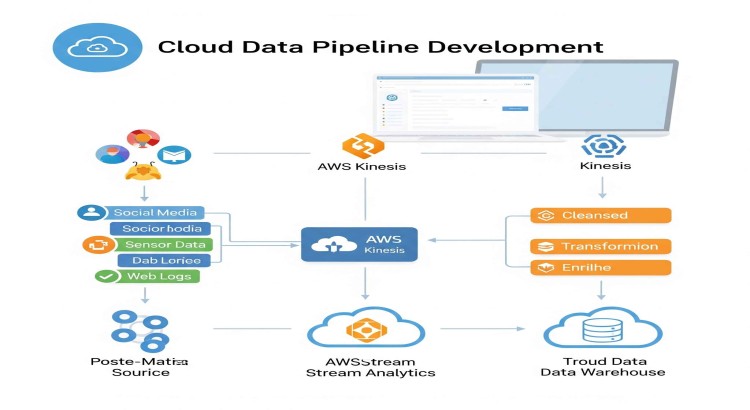
- Data Source Identification & Assessment: Identifying and analyzing all relevant data sources (e.g., databases, APIs, logs, streaming data, SaaS applications). Assessing data formats, volume, velocity, and existing access methods.
- Pipeline Architecture Design: Designing a scalable and resilient cloud data pipeline architecture. This includes selecting appropriate cloud services (e.g., AWS Glue, Azure Data Factory, Google Cloud Dataflow), defining data flow, staging areas, and error handling mechanisms.
- Data Ingestion Implementation: Building automated processes to ingest data from various sources into cloud storage (e.g., AWS S3, Azure Data Lake Storage, Google Cloud Storage). This can involve batch processing, real-time streaming, or CDC (Change Data Capture).
- Data Transformation (ETL/ELT) Development: Developing scripts or workflows for data cleaning, standardization, enrichment, and transformation. This includes defining data quality rules and ensuring data consistency.
- Data Loading into Data Warehouse/Lake: Implementing processes to load transformed data into your chosen cloud data warehouse (Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse Analytics) or data lake.
- Orchestration & Scheduling: Setting up orchestration tools (e.g., Apache Airflow on cloud, AWS Step Functions, Azure Data Factory, Google Cloud Composer) to schedule, monitor, and manage pipeline execution.
- Monitoring & Alerting: Configuring monitoring for pipeline health, data quality, and performance. Setting up alerts for failures or anomalies to ensure timely intervention.
- Error Handling & Retries: Implementing robust error handling, logging, and retry mechanisms within the pipelines to ensure data integrity and resilience.
- Security & Compliance: Ensuring data pipelines adhere to security best practices (encryption, access control) and compliance requirements (e.g., GDPR, HIPAA).
- Documentation & Knowledge Transfer: Providing comprehensive documentation of the data pipeline architecture, code, and operational procedures. Training your data team on pipeline management and troubleshooting.
Tools Utilized:
- Cloud Data Services:
- AWS: AWS Glue, AWS Kinesis, AWS S3, AWS Lambda, AWS Step Functions, Amazon Redshift.
- Azure: Azure Data Factory, Azure Event Hubs, Azure Data Lake Storage, Azure Synapse Analytics.
- Google Cloud: Google Cloud Dataflow, Google Cloud Pub/Sub, Google Cloud Storage, Google BigQuery, Google Cloud Composer.
- Orchestration: Apache Airflow, Luigi.
- Programming Languages: Python, SQL, Scala, Java.
- Version Control: Git, GitHub, GitLab.
- Monitoring: CloudWatch, Azure Monitor, Google Cloud Monitoring, Grafana.
- Data Warehouses/Lakes: Snowflake, Databricks.
Skills Involved:
- Cloud Data Engineering: Deep expertise in cloud data platforms (AWS, Azure, GCP).
- ETL/ELT Methodologies: Strong understanding of data extraction, transformation, and loading processes.
- Programming: Proficiency in Python, SQL, and potentially Scala/Java.
- Data Modeling: Knowledge of relational and dimensional data modeling for analytics.
- Big Data Technologies: Familiarity with concepts like distributed processing, streaming.
- Database Management: Experience with various database types (relational, NoSQL).
- Orchestration & Automation: Expertise in pipeline scheduling and workflow management.
- Data Quality & Governance: Ability to implement data validation and quality checks.
- Troubleshooting: Strong diagnostic skills for data pipeline failures.
- Security & Compliance: Understanding of data security and privacy regulations.
Future Predictions/Considerations:
Future data pipelines will increasingly leverage real-time streaming, AI/ML for automated data quality and transformation, and data mesh architectures for decentralized data ownership. Data governance and observability across complex pipelines will become paramount. The demand for "data products" delivered directly by pipelines will grow, blurring the lines between data engineering and analytics.
Why Choose Me?
As a Cloud Data Analytics Engineer with 7 years of experience, I excel in designing and implementing scalable data pipelines and analytics solutions on cloud platforms. My background includes developing and optimizing cloud-based data warehouses and ETL processes, improving data processing efficiency by 30% and enabling real-time analytics. I am proficient in leading platforms like BigQuery, Redshift, and Snowflake, ensuring your raw data transforms into actionable insights.
Service Features
- ● Data Source Assessment & Requirements Gathering
- ● Cloud Data Pipeline Architecture Design
- ● Implementation of 1-2 Data Ingestion Flows
- ● Basic Data Transformation Logic Development
- ● Data Loading to Target Data Warehouse/Lake
- ● Pipeline Orchestration & Scheduling Setup
- ● Basic Monitoring & Alerting
- ● Documentation & Knowledge Transfer
About the Seller
Basic
Related Services



Join as a freelancer or client
Join as a Freelancer
Join as a Client